Prologue: Software Practices Are Only Best Within Specific Contexts
Have you ever attended a conference session with a presenter that is very passionate about a new process? They believe that everyone should be using the process. Often, I have doubts that the process will work for my team, but the presenter seems to imply that I don’t fully understand what they are attempting to convey; and perhaps I just need to start trying to make the change to realize the value of it. While this could be true, I have learned over the years that many people pitching process changes that provided enormous return on value for their software development teams, are pitching solutions that might not work well for other software development teams. The presenters are not trying to sell me something I don’t need, and they are not being dishonest, they are usually just considering their solution from a single context.
And what do I mean by context? A context is the processes, people, tools, networks, languages, deployment models, and culture in which software is produced and deployed. A practice that is optimal in one context may not be optimal in another, just like the best practices for building a house may differ from the best practices for building a bridge or a skyscraper. Some aspects of context affect some best practices more than others. For example:
- Your deployment model is an aspect affecting the processes you choose. It is possible to use the CI/CD process when you deploy to a web app, but impossible to use CI/CD when deploying software to chips that are embedded in the engines of airplanes.
- StandUp meetings might be ideal for a scrum team with all members co-located and starting work at the same time; but a waste of time for a team of four all sitting at the same desk doing mob programming.
This series of articles looks at software practices one by one to highlight what contexts each practice may work well in, and contexts where the practice may not work well, or may even be counter-productive.
Here is an example of a context constrained best practice. After graduating from college, a developer created static web sites for years, modifying html pages and JavaScript and committing code changes to GitHub while also maintaining a web server and uploading file changes to the web site using FileZilla. But then he discovered Netlify which uses the JamStack process which makes it incredibly easy to commit his changes to GitHub and have them validated, compiled, optimized, and automatically deployed to the production web site. Now he is telling everyone they should use JamStack and Netlify for all web development. And perhaps they should, if they are deploying static public web sites. But some developers are deploying to internal web sites. Some developers have database changes and dependencies on code from other teams. Some developers have mission critical applications that can’t risk ten seconds of downtime due to an error in production. These are different contexts and the Netlify/JamStack approach may be undesirable for these contexts.
In short, any “best practice” applies within a specific context, and is unlikely to apply to all contexts. We need to identify the best practices that we can apply to our contexts. Some people are dogmatic about their ideas of best practices. They believe a process should always be applied in all software contexts, but personally, I think there may be no software practice that is always best. I think there are many contexts in which some process recommendations are poor choices.
Subsequent articles will examine processes one at a time, explaining why the processes are poor choices for some contexts. The list of process recommendations that will be shown to be poor choices in some contexts include the following: Scrum, TDD, Pair-Programming, Continuous Deployment (CD), Story Points, Velocity, Code Reviews, Retrospectives, Management By Objectives (MBO), and metrics.

Main Content: Is CI/CD Right For You?
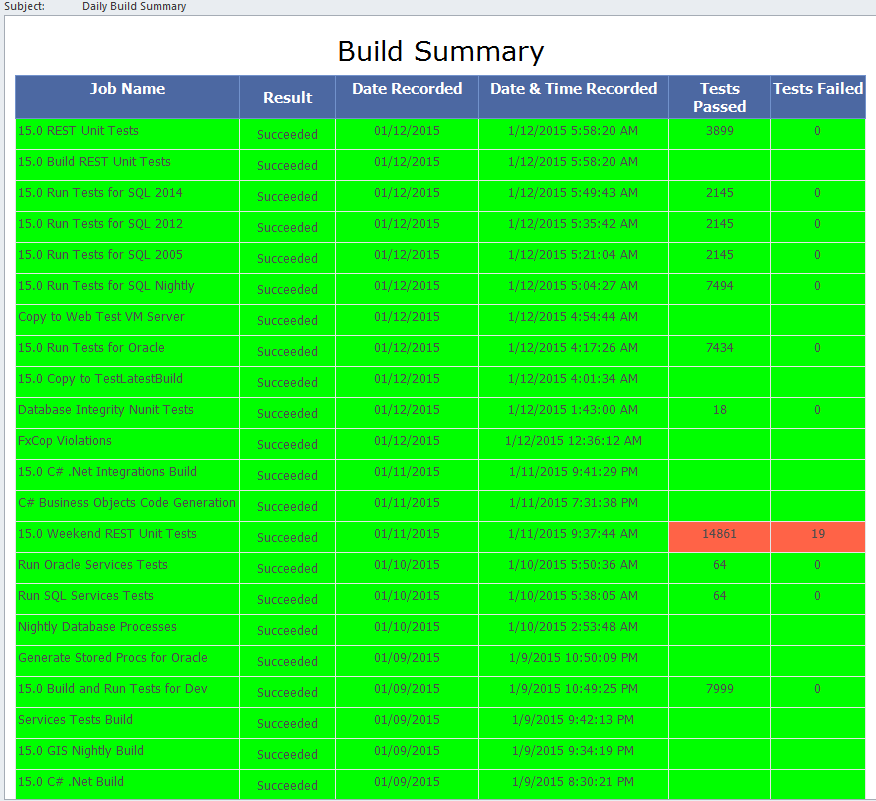
The acronym CI/CD stands for “Continuous Integration” and “Continuous Delivery” and also “Continuous Deployment”. Usually, perhaps always, CI needs to be implemented before either of the CDs can be implemented. CI refers to coders pushing code changes to a shared team repository frequently, often multiple times per day. In many contexts, a build of the software is started once the push into the shared code base is complete. In some contexts, builds of the shared repository may occur on a regular basis such as every hour. The benefit of automated builds is to quickly identify cases in which the code changes made by two developers conflict with each other.
Along with running a build, many CI pipelines perform other tasks on the code. These tasks include “static code analysis” aka “linting” to determine if the code follows code formatting standards and naming conventions as well as checking the code for logic bugs and bugs that create security vulnerabilities. Static code analysis may detect if new and unapproved third-party libraries were introduced, or that code complexity levels exceed a tolerance level, or simply if a method has more lines of code within it than is approved by company standards. If the code compiles and passes the static code analysis checks, it may then have a suite of unit tests and integration tests executed to verify no existing logic in the application was broken by the latest code changes.
CI encompasses two practices; frequent code pushes and automated builds. Some of the benefits of frequent code pushes include:
- Developers get feedback more quickly if they have made changes that conflict with something other developers committed,
- Builds based on the shared repository are less likely to conflict with changes from other developers when the code base the developer is working from is more current and the number of changes made to the code is fewer,
- Reviewing code of other developers is easier when developers check in frequently because it is likely there are fewer code changes to review,
- Since code reviews take less time, they interrupt the flow of the developer reviewing the code less,
- Since code reviews take less time other developers are more willing to perform the code review and are more willing to do it soon.
Some of the benefits of automated builds include:
- A relatively quick response if code pushed to a shared repository causes a build failure,
- Relatively quick feedback from static code analysis tools to identify problems,
- Relatively quick feedback from unit tests and integration tests if code changes created bugs in the application.
CI is very beneficial and invaluable to many software development teams, but it is not necessarily a benefit in all software development contexts. Some contexts that may gain little value from CI include:
- When there is only a single developer on the project and a CI environment does not already exist,
- When developers are exploring a new programming language for development. In this case, the time required to set up the CI may be more than it is worth for something that might get discarded,
- When the coding language is a scripting language and there is no compile step,
- When a team has no automated build currently and creates the compiled version of their product on their local machines to deploy to production.

Should You Make a Process Change?
When evaluating if any process like CI is good for you, the most important factors in making the assessment are:
- Is it worth my (our) time to implement the process or practice?
- Will the process improve our product quality?
If the process does not improve quality, which means it doesn’t decrease bugs or decrease security vulnerabilities or improve application performance; and it takes significantly more time to implement the process than it will save by not implementing the process, then you should probably not implement it.
Should You Consider CI?
With this definition of CI and criteria for assessment, I believe that most development teams should consider implementing CI into their development process.
CD Benefits and Drawbacks
The other aspect of CI/CD is CD. CD stands for either “Continuous Delivery” or “Continuous Deployment” or both. Both terms imply that successful software builds get automatically pushed into an environment where it can be tested or used, but some teams prefer to use “Delivery” for non-production environments and reserve “Deployment” for the “production” environment. Also, some teams don’t really automatically deploy the software to an environment after it successfully builds. Instead, the deployment to an environment requires a button click by an authorized person to proceed.
CD has less adoption than CI, partially because CI is generally a pre-requisite to CD, but mostly because CD is not a good deployment strategy for many software products. In fact, CD is not even possible for software embedded onto chips and placed into airplanes, cars, refrigerators, rockets, and many other devices. Nor is CD practical for most desktop applications and applications delivered to phones and other devices through an app store. CI/CD is most likely useful in the deployment of web applications and web APIs.
Some of the benefits of Continuous Delivery to a non-production environment include:
- It forces you to codify everything. That means you need to figure out how to automate and automatically apply the environment specific configuration values. You may need to learn how to use containers to simplify deployment and to version control and automate all aspects of devops,
- It creates possibilities. For example, once you have taken the time to create a pipeline where your automated build can flow into a deployed environment, you discover you can now easily automate your pen tests and stress tests against a test environment,
- A developer can test some changes in a deployment environment that they can’t test in the developer’s environment (aka: works on my machine), such as:
- Changes related to threading behavior in applications,
- Changes related to users from multiple devices simultaneously using the application,
- Stress testing the scalability of an application,
- Testing features affected by security mechanisms such as OAuth and TLS.
- Developers can get new features into functioning environments faster for the benefit of others,
- Developers can deploy to testing environments easily without waiting on the devops team or IT team to perform a task for them,
- It becomes easier to create a totally new environment. Perhaps you currently have just production and test. Now you can add a QA environment or a temporary environment relatively easily if all the deployment pieces are automated.
Some of the benefits of Continuous Deployment to a production environment include:
- Developers can get new features and fixes to production faster. This is very valuable for static sites. This is a core feature of most JamStack sites.
- Developers can deploy without waiting on the devops team or IT team to perform a task for them.
Some of the challenges of Continuous Delivery to a non-production environment include:
- Applying changes to databases in coordination with changes to code,
- Interruption of testing by others currently in process,
- Insuring the correct sequence of deployments when multiple teams are deploying to a shared testing environment and some changes depend on sequence
Some of the impediments of Continuous Deployment to a production environment include:
- The need for the software to be burned into a physical chip,
- The need for the software to be published through an app store,
- The need for lengthy integration testing and/or manual testing before production, often due to the need to insure the software is correct if it is used to keep people alive,
- The desire by the company to find any problems with the software before customers interact with it.
Should You Consider CI/CD?
Should you adopt CI and/or CD? That is a question you need to answer for yourself. Not only should you consider the benefits and value CI/CD may bring to your development process, you should always also consider if adopting a process is more valuable than other changes you could make. Just because we recognize the value in implementing a specific change doesn’t mean we should implement it right away. Perhaps it is more valuable to your company to complete a project you are working on before implementing CI/CD. Perhaps it is more valuable to wait six weeks for the free training sessions on TeamCity and Octopus Deploy to be available if those are the tools you are considering to use for CI/CD. Perhaps you are considering moving from subversion to git. If so, you should probably make that change before you build a CI/CD solution, otherwise you may need to rebuild your CI/CD pipeline completely. Also, going from manual builds to CI/CD is unlikely to be something completed in a short time frame. It is something you will progressively implement and adopt more aspects of over time.
I believe that most development teams should consider implementing “Continuous Delivery” into their development process. “Continuous Deployment” to production is probably primarily of value to teams deploying static web sites, and maybe a few sites with small amounts of data or unimportant data.