While it’s important to execute projects well, the true measure of success lies in the quality, impact, and longevity of the product, not the completion of the projects that built the product. Sacrifice a project for the good of the product.
If you have been working on a software development project that you expect to take three years to complete, and you learn something new along the way, or a new technology like chap-gpt comes along that gives you new ideas, don’t be afraid to cancel the project and call the project a failure. The product is more important than the projects used to build it. Always do what is best for the product, even if it means a project is delayed or cancelled.
I’ll admit this post would have been more valuable fifteen years ago, but those still using the ASP.Net Membership provider tables and stored procs that came with .Net Framework 2.0, 3.0, or 4.8 my like the performance boost you can get from these changes. The Membership tables were designed with two major flaws, in hindsight. One, the primary keys are guids, which provide terrible performance, and two, they assumed most installations would have multiple applications using the same membership table, which I think they do not. But Microsoft made the application ID, a guid, part of every key in every query. If your application only has a single application ID, you can change the stored procs to not consider the application ID as part of the query, and change the indexes to remove application ID as well. The change scripts are provided below:
alter PROCEDURE [dbo].[aspnet_Membership_GetUserByEmail]
@ApplicationName nvarchar(256),
@Email nvarchar(256)
AS
BEGIN
IF( @Email IS NULL )
SELECT u.UserName
FROM dbo.aspnet_Users u, dbo.aspnet_Membership m
WHERE
u.UserId = m.UserId AND
m.LoweredEmail IS NULL
ELSE
SELECT u.UserName
FROM dbo.aspnet_Users u, dbo.aspnet_Membership m
WHERE
u.UserId = m.UserId AND
@Email = m.LoweredEmail
IF (@@rowcount = 0)
RETURN(1)
RETURN(0)
END
GO
alter PROCEDURE dbo.aspnet_Membership_FindUsersByEmail
@ApplicationName nvarchar(256),
@EmailToMatch nvarchar(256),
@PageIndex int,
@PageSize int
AS
BEGIN
-- Set the page bounds
DECLARE @PageLowerBound int
DECLARE @PageUpperBound int
DECLARE @TotalRecords int
SET @PageLowerBound = @PageSize * @PageIndex
SET @PageUpperBound = @PageSize - 1 + @PageLowerBound
-- Create a temp table TO store the select results
CREATE TABLE #PageIndexForUsers
(
IndexId int IDENTITY (0, 1) NOT NULL,
UserId uniqueidentifier
)
-- Insert into our temp table
IF( @EmailToMatch IS NULL )
INSERT INTO #PageIndexForUsers (UserId)
SELECT u.UserId
FROM dbo.aspnet_Users u, dbo.aspnet_Membership m
WHERE m.UserId = u.UserId AND m.Email IS NULL
ORDER BY m.LoweredEmail
ELSE
INSERT INTO #PageIndexForUsers (UserId)
SELECT u.UserId
FROM dbo.aspnet_Users u, dbo.aspnet_Membership m
WHERE m.UserId = u.UserId AND m.LoweredEmail LIKE @EmailToMatch
ORDER BY m.LoweredEmail
SELECT u.UserName, m.Email, m.PasswordQuestion, m.Comment, m.IsApproved,
m.CreateDate,
m.LastLoginDate,
u.LastActivityDate,
m.LastPasswordChangedDate,
u.UserId, m.IsLockedOut,
m.LastLockoutDate
FROM dbo.aspnet_Membership m, dbo.aspnet_Users u, #PageIndexForUsers p
WHERE u.UserId = p.UserId AND u.UserId = m.UserId AND
p.IndexId >= @PageLowerBound AND p.IndexId <= @PageUpperBound
ORDER BY m.LoweredEmail
SELECT @TotalRecords = COUNT(*)
FROM #PageIndexForUsers
RETURN @TotalRecords
END
go
ALTER PROCEDURE [dbo].[aspnet_Membership_FindUsersByName]
@ApplicationName nvarchar(256),
@UserNameToMatch nvarchar(256),
@PageIndex int,
@PageSize int
AS
BEGIN
-- Set the page bounds
DECLARE @PageLowerBound int
DECLARE @PageUpperBound int
DECLARE @TotalRecords int
SET @PageLowerBound = @PageSize * @PageIndex
SET @PageUpperBound = @PageSize - 1 + @PageLowerBound
-- Create a temp table TO store the select results
CREATE TABLE #PageIndexForUsers
(
IndexId int IDENTITY (0, 1) NOT NULL,
UserId uniqueidentifier
)
-- Insert into our temp table
INSERT INTO #PageIndexForUsers (UserId)
SELECT u.UserId
FROM dbo.aspnet_Users u, dbo.aspnet_Membership m
WHERE m.UserId = u.UserId AND u.LoweredUserName LIKE @UserNameToMatch
ORDER BY u.UserName
SELECT u.UserName, m.Email, m.PasswordQuestion, m.Comment, m.IsApproved,
m.CreateDate,
m.LastLoginDate,
u.LastActivityDate,
m.LastPasswordChangedDate,
u.UserId, m.IsLockedOut,
m.LastLockoutDate
FROM dbo.aspnet_Membership m, dbo.aspnet_Users u, #PageIndexForUsers p
WHERE u.UserId = p.UserId AND u.UserId = m.UserId AND
p.IndexId >= @PageLowerBound AND p.IndexId <= @PageUpperBound
ORDER BY u.UserName
SELECT @TotalRecords = COUNT(*)
FROM #PageIndexForUsers
RETURN @TotalRecords
END
GO
ALTER PROCEDURE [dbo].[aspnet_Membership_GetUserByName]
@ApplicationName nvarchar(256),
@UserName nvarchar(256),
@CurrentTimeUtc datetime,
@UpdateLastActivity bit = 0
AS
BEGIN
DECLARE @UserId uniqueidentifier
IF (@UpdateLastActivity = 1)
BEGIN
-- select user ID from aspnet_users table
SELECT TOP 1 @UserId = u.UserId
FROM dbo.aspnet_Users u, dbo.aspnet_Membership m
WHERE
@UserName = u.LoweredUserName AND u.UserId = m.UserId
IF (@@ROWCOUNT = 0) -- Username not found
RETURN -1
UPDATE dbo.aspnet_Users
SET LastActivityDate = @CurrentTimeUtc
WHERE @UserId = UserId
SELECT m.Email, m.PasswordQuestion, m.Comment, m.IsApproved,
m.CreateDate, m.LastLoginDate, u.LastActivityDate, m.LastPasswordChangedDate,
u.UserId, m.IsLockedOut, m.LastLockoutDate
FROM dbo.aspnet_Users u, dbo.aspnet_Membership m
WHERE @UserId = u.UserId AND u.UserId = m.UserId
END
ELSE
BEGIN
SELECT TOP 1 m.Email, m.PasswordQuestion, m.Comment, m.IsApproved,
m.CreateDate, m.LastLoginDate, u.LastActivityDate, m.LastPasswordChangedDate,
u.UserId, m.IsLockedOut,m.LastLockoutDate
FROM dbo.aspnet_Users u, dbo.aspnet_Membership m
WHERE
@UserName = u.LoweredUserName AND u.UserId = m.UserId
IF (@@ROWCOUNT = 0) -- Username not found
RETURN -1
END
RETURN 0
END
GO
alter PROCEDURE [dbo].[aspnet_Roles_RoleExists]
@ApplicationName nvarchar(256),
@RoleName nvarchar(256)
AS
BEGIN
IF (EXISTS (SELECT RoleName FROM dbo.aspnet_Roles WHERE @RoleName = LoweredRoleName ))
RETURN(1)
ELSE
RETURN(0)
END
GO
drop index aspnet_Membership_index on [dbo].[aspnet_Membership]
go
CREATE CLUSTERED INDEX [aspnet_Membership_index] ON [dbo].[aspnet_Membership]
(
[LoweredEmail] ASC
)WITH (FillFactor=95) ON [PRIMARY]
GO
CREATE NONCLUSTERED INDEX [IX_ApplicationId] ON [dbo].[aspnet_Membership]
(
[ApplicationId] ASC
)WITH (FillFactor=95)
GO
drop index aspnet_Users_index on [dbo].[aspnet_Users]
go
CREATE UNIQUE CLUSTERED INDEX [aspnet_Users_Index] ON [dbo].[aspnet_Users]
(
[LoweredUserName] ASC
)WITH (FillFactor=95)
GO
drop index aspnet_Users_index2 on [dbo].[aspnet_Users]
go
CREATE NONCLUSTERED INDEX [aspnet_Users_Index2] ON [dbo].[aspnet_Users]
(
[LastActivityDate] ASC
)WITH (FillFactor=95)
CREATE NONCLUSTERED INDEX [IX_AspNet_Users_ApplicationID] ON [dbo].[aspnet_Users]
(
[ApplicationId] ASC
)WITH (FillFactor=95)
GO
Text Boxes on Forms and Reports in Microsoft Access allow you to configure the field to display “Rich Text” instead of “Plain Text” by setting the “Text Format” property of the control. This allows you to use HTML formatting in the field and display portions of the field using bold, italics, underline, and other enhancements.
However, when your data is coming from a SQL Server (or other DBMS), through linked tables, you can only choose to configure the control to support “Rich Text” when the field has a size of 256 bytes or greater.
Therefore, you need to go back to your source database (SQL Server), increase the size of the field so that it is 256 or larger, then go back to Access and Relink the table. After that, you should be able to choose Rich Text for the field on the form.
When the linked field length is too short, you will get this message from Microsoft Access “The setting you entered isn’t valid for this property.” when you try to change the control.
When the product owner provides a well-groomed backlog, you may think selecting the next feature to work on is obvious, but often it isn’t. A development team should consider many factors before picking an item from the product backlog to work on.
Here are some examples of how features may be selected for development:
Product Owner in Charge. In some contexts, [what is a context?], the development team is treated as an assembly line to deliver features, and the development team has little or no input into which features they will work on. A drawback of this context is that the development team isn’t allowed to provide an alternative sequence of features that could minimize development costs and increase throughput and quality. Additionally, allowing the development team to have input on the decisions can increase their commitment to completing the features as well as strengthen their “buy-in” to the product and process, which is known to increase morale and quality.
PMO in Charge. In some contexts, the development team supports several products and may work on features for a different product each iteration. In contexts where the development team has some input into feature selection decisions, it is often beneficial to the team to establish a Product Management Office (PMO) that works with each Product Owner to get a consensus agreement from the Product Owners choosing which feature, which Product Owner’s product, will get some development time during the next cycle. When the delivery team works on feature requests directly from customers, the team may find it helpful to establish a customer advisory board (CAB) that receives most of the large requests and provides input and direction to the development team about which features will be most valuable for most clients.
Too Many in Charge. In some contexts, development teams switch from feature to feature as their bosses, managers, and clients demand they stop working on one feature and switch to another to satisfy the demands from a specific customer or the whims of a forceful product owner or manager. Many drawbacks and inefficiencies exist in such a context. Developers are often demoralized by the inability to finish what they start so output is below expectations and quality is poor. Context switching wastes time as developers need to re-acquaint themselves with something new and lose the design ideas that existed only in their heads for the features they had been working on.
Waterfall. In non-agile environments, new projects and feature requests may get delivered to the development team(s) with the expectation that an expected delivery date for the feature will be provided soon even though none of the Product Owners have an idea of the current backlog for the delivery team. Equally unfortunate is the fact that the delivery teams may stop the feature development on other products when the new request comes in because they are more interested in learning what the new feature is, and they will spend time doing some design and development on it to return an estimate of the expected delivery date.
No One in Charge. In contexts without delivery expectations or engaged product owners, developers may drift into spending a lot of time developing features that are very unlikely to ever be used, or in developing features completely different than what the product owners expected. Additionally, developers may context switch often, working on one feature for a while and then another, leaving them with much started and nothing completed when the product owner eventually asks to see some results.
Customer in Charge.Some contexts have a particularly demanding or upset client that seems to be dictating the features a team will deliver. I once worked on a team where we obtained a new client (I will call them ACME), our largest client ever by far, and they soon demanded software improvements to help them meet their needs. So over the course of two years most of the features we delivered were those requested by ACME. We even joked that our developing methodology was ADD (ACME driven development) as opposed to Business Driven Development (BDD) or Domain Driven Development (DDD).
Development Team in Charge.Finally, in contexts where the team wants to work on the features with the greatest return on investment (ROI), developers often collaborate with product owners to calculate the ROI of each feature, providing a value for the feature from the perspective of those who will be using the software, and the developers providing an estimate of the difficulty to deliver the feature and the risks involved. Minimal risk, easy to develop, high value features are usually developed first; and high risk, difficult to develop features are delivered later even if their value is high. The textbook formula for ROI is value divided by development cost; and those with the highest ROI scores should be worked on earliest.
The Optimal Context
The optimal context for obtaining the best ROI from software development is a context in which the development team wields the majority of the power to decide the sequence in which features will be developed. The reason for this is the development team has the best knowledge of the changes needed to implement a feature and can suggest the best sequence of feature delivery to minimize development costs. In a healthy context, the development team will desire input from the product owners to identify the features with the highest value and attempt to deliver those first, and the product team will understand and usually be happy with the decisions made by the development team.
However, there are some contexts in which someone other than the development team can make better decisions about what to develop next. One context is during chaos caused by bad software that needs to be fixed immediately or important clients and customers threatening to leave if their demands are not met quickly. Another context is when the team is comprised of junior developers or people new to a product. In this latter context, it may be best to allow the product owner to determine the sequence in which the team will work on features until the team has learned the software architecture, development processes, and product domain.
Return On Investment (ROI) for Feature Selection
Although several of the contexts listed above may include the ROI (value/cost) when assigning the priority of feature development, the last context, Developer in Charge, is usually the context that provides the most accurate ROI calculation. The reason for this is that both the value and cost of a feature not yet developed change over time, but, with exception of time-sensitive features, the costs of a feature usually change more significantly than the value. The cost of developing a feature can be affected by many factors including:
The sequence in which features are delivered. In some cases, Feature A may be estimated to cost 100 hours to develop, and Feature B may be estimated to cost 40 hours to develop after Feature A. But if the sequence is reversed, and Feature B is developed first, B still costs 40 hours, but Feature A can re-use some of the code developed by Feature B and Feature A only costs 80 hours to develop.
The specific individuals assigned to do the work affect the cost, often substantially. A feature assigned to a junior developer available at the time may take 100 hours, whereas a senior developer may be able to deliver the same feature in 20 hours. Waiting for the senior developer to be available at the next iteration may be more efficient.
As developers write code and learn new technologies they sometimes discover a new approach to implement a feature that was previously not considered. The new approach may not only take less time, but also result in higher quality. This is one reason for delaying many technical decisions until you have more knowledge.
Hopefully, it is obvious that delivering the features with the highest ROI is most valuable to the company. If your organization is not using ROI as a factor in choosing what to work on next, then your team may be wasting time (as explained in Lean/Agile development philosophy), by not doing what is most valuable first. Allowing the development team to be the primary selector of the sequence in which to develop features may require a change in your team and company culture, and how management hierarchies are organized; but it may be necessary to become more efficient.
Challenges of Calculating ROI
At this point you may accept the premise that choosing features to work on based on their ROI is so sensible that everyone should use this approach, but the reality of software development is much more complicated. First of all, determining the ROI of each feature is very difficult. Developers know that estimating the time to deliver a feature is difficult but assigning a dollar amount to the value of a feature delivered may be even more difficult. So not only are both the numerator and the denominator of our ROI calculation fuzzy numbers, there is also a lot of room for variance within those two values. What is the ROI for delivering an order entry screen without date pickers for the date fields versus an order entry screen with date pickers for the date fields? What is the ROI of delivering a grid full of data that lacks the ability to filter the data versus a grid full of data that can filter the data? What is the incremental development cost of adding each desired sub-feature to the feature? Can you first deliver a basic set of features and the later deliver the enhancements? All these options and variables make ROI calculations for a single feature very subjective.
Challenges for using ROI for Feature Selection
You need to take time to perform ROI calculations and record them with the feature in your tracking system.
You need to have the people that best know how to value the feature from the customer perspective available to provide an estimated feature value.
You need to have the people that can best estimate the cost and risks of delivering the feature available to spend time to calculate an estimate.
The value of an undelivered feature can change over time as market and user needs change or as other options become available that help customers and users resolve their business needs.
The effort required to deliver a feature can change over time as the skills and knowledge of the developers change, but also as the technologies and frameworks of the software evolve and improve.
The cost to deliver some features may be reduced when the feature is delivered along with other features. Imagine having three separate requests to add a checkbox for different purposes to the same user interface, and the value of the first checkbox is deemed very high, but the value of the other two checkboxes is not. Each has the same development cost to deliver. However, if all three are delivered together the development costs decrease significantly because all three database changes can be made at once, and all three business object changes can be made at once, and all three UI changes can be made at once. Therefore, given that the cost of implementing checkboxes two and three, when implemented along with checkbox one, is reduced significantly, the ROI of checkboxes two and three would increase and it would make sense to deliver them along with checkbox one.
Another reason to implement features with lower ROI is to use them as a test case for a new technology. Perhaps you know you want to start encrypting data for millions of transactions, a feature with a lot of risk if it is delivered incorrectly. Therefore, you choose a lower priority feature from the backlog that also needs to encrypt data, but only in a small number of use cases. You can implement the feature with the lower ROI first to work out the difficulties of implementing the new encryption technology before using it on a more important feature.
There are more reasons for choosing to work on features that don’t have the highest ROI, and some of those reasons include:
You have a developer or two that need to be assigned some work, but the developers don’t have the skills to tackle the features with the highest ROI.
You have a junior developer or intern, and you want them to comfortably work on some features that will help them best learn your software and development processes; or you want them to work on some features that won’t have a significant impact if the developer makes a mistake.
ROI includes a time component. Value may decrease over time. One feature may provide a greater ROI initially, but another feature may provide a greater ROI over a longer time period. If a feature is working poorly in Windows 8 but works perfectly on Windows 10, the longer you wait to deliver the feature the less value the feature will provide when finally delivered because more of your customers have migrated to Windows 10.
ROI value may increase over time. We might estimate the value of a feature to be worth $50,000, but it may be more accurate to say that the feature will increase our revenue by $1,000 per day, thus its value is increasing over time. So, when we calculate the value for ROI and compare the ROI for two features, we need to consider the timeframe of the ROI for each.
Developers often prefer to work on features that provide the best ROI in the long term, which can include rewriting some old, buggy, difficult to maintain software using current frameworks and technologies. But if customers are angry and demanding the bugs get fixed ASAP, it may be best to spend time fighting the current fires, knowing that the very code you are fixing will be thrown out and replaced within a few months. It feels like a waste, but you must survive the short term to exist in the long term. If that phrase doesn’t make sense, consider this analogy: Fighting global warming may be the most important challenge we face and where we should focus our resources, but if the largest nations in the world are on the brink of a nuclear war, then focusing resources on resolving that challenge in the short term becomes more important than fighting global warming; because if don’t deal with the short term problem, no one may survive to address the long term problem.
Should the Development Team Do Activities Other Than New Features?
Some readers may feel there is a lot to consider to effectively use ROI to drive feature delivery but using ROI to determine what a development team does next is only part of the equation. There are activities you may find more valuable to your development process to work on instead of developing new features. If you have adopted a Continuous Process Improvement mindset, then, by definition, you believe you should often spend time considering how you can improve your processes; and in this context how you can improve your software development processes. What if you could make a change to your software development process that would increase delivery speed of new features by 50%? I suspect you would want to implement that change. But that change is not a new feature. It is more likely a DevOps change or a significant refactoring of the code, or a process change such as adopting Kanban. Regardless of what the change is, the change is likely to require time from your developers to implement and adopt. That means that instead of developing new features, your developers are going to spend their time on other activities. We now realize that there are activities other than developing new features that your development team should consider spending time on. Specifically it means that your software product and delivery process will get a better ROI when the development team performs activities like improving DevOps, fixing bugs, refactoring code, training, writing unit tests, and writing developer documentation than when they are developing new features. This is not to say that these activities always, or even most of the time, provide a better ROI than delivering new features, but it does mean that when the decisions are being made about what the development team should do next, the decision makers should not be considering only new features to deliver.
Evaluating the ROI of Possible Development Team Activities
The following diagrams provide examples of a backlog of activities that a development team could perform. The backlog has four types of items: New Feature, Fix Bug, Refactor, and DevOps change. In the upper half of the first diagram, the team chooses to implement a New Feature that has a development cost of 2, and the value perceived by the customer receiving the feature is 12 (100 – 88).
In the lower half of the above diagram, the development team chooses to fix a bug. The bug has a cost of 3 and increases the customer’s perceived value of the software by 2 (102 – 100). For both developers and businesspeople, the examples above are easily understood.
The following examples attempt to convey the value of Refactoring, DevOps Changes, and Training using the same principles of ROI.
In the upper half of the diagram below, the development team chooses to refactor some of their existing code. This code is delivered to production, but the customer perceives no value in the change (102 – 102 = 0). From the perspective of the customer, the features of the software have not changed (although in some cases refactoring may include noticeable performance or security improvements). But what you should notice is that the cost of several items in the Backlog changed after the refactoring was implemented. The most common effect of a successful refactoring is that delivering future features becomes easier. Of course, as with ROI calculations, it is difficult to estimate the impact on cost that a refactoring will have on other features. Additionally, refactoring code to support a newer framework or technology may be beneficial to changes made a year or more in the future, but not particularly valuable to the other features in the immediate backlog.
The lower part of the above diagram begins to show the impact of a change in DevOps. For purposes of this article, a DevOps change refers to a change made to the processes and tools used to build, unit test, validate, and deliver software. A DevOps change could imply that the team took time to automate builds instead of performing manual builds, or to automate deployment to a test environment so the QA team could test the latest build more quickly and provide feedback more quickly. Regardless, the DevOps change does not (in the case) affect production, and there is no deployment. The customer does not gain any direct value from the DevOps change. But, like refactoring, the DevOps change has a positive impact on subsequent development as shown in the diagram below. In this example, the Cycle Time, the speed at which a feature goes from “started” to “delivered” was reduced for most features developed after the DevOps enhancement. By investing time to make this DevOps improvement, all future development can be delivered faster. In this specific, admittedly fictional, example, the time for a feature with a size Estimate of “8” has been reduced from 25 to 22, the time for a feature with a size estimate of “5” reduced from 12 to 10, the time for a feature with a size estimate of “3” from 5 to 4; while the estimate for a feature with a size estimate of just “2” remains at 2.
One additional activity included in the lower part of the above diagram is developer training. The impact of developers taking time for training, such as learning new design techniques, coding techniques, or development product features, may be to increase the speed at which developers can produce features. So, like refactoring and DevOps enhancements, a team may consider developer training to be the activity that it is most valuable for a development team to do next.
Doing Multiple Things At The Same Time
The entire article up to this point assumes that development teams do one thing at a time. In reality, teams with more than three people usually do several things at the same time. Most teams, even many Kanban teams, will pick several features, bugs, and other activities to work on over the course of a few weeks, or during the next iteration. One benefit of doing multiple activities is that some team members are usually always working on new features, which is what product owners and customers are primarily interested in. Working on multiple activities at the same time allows some feature progress to continue even as other team members spend months on DevOps or refactoring activities.
Recap
There is value in understanding who decides what the development team will do next.
There is value in recognizing that the development environment context strongly influences who makes that decision.
Return on Investment (ROI) should be a primary factor in determining what is done next.
Developers usually can provide the best ROI estimates.
ROI is a subjective measure.
Activities such as refactoring and DevOps improvements may provide a better ROI than developing new features.
Ask a consultant for the solution to a problem and the most likely answer is, “It depends.” This is a fair and honest response that reflects the reality that the best solution to a problem in one context may not be the best solution for a similar problem in another context.
But what is meant by context? A context is the collection of elements that may affect the success of a change you introduce. In software development, context includes the software architecture, the experience level of the development team, the processes used to manage projects, the environment into which the software is deployed, and more. Each of the elements of the software development context may have some impact on a team’s ability to successfully implement a new practice into their environment.
An example of a new practice you could consider is Test Driven Development (TDD). Some software development teams use TDD and accrue a lot of benefit. But will it benefit your team? The answer is, “It depends”. It depends upon your software development context. If your developers are primarily modifying an existing codebase, especially in an environment that doesn’t support unit tests, then TDD may not be practical for your team.
Another example is the practice of Continuous Deployment. A lot of teams that deploy web sites love the ability to continuously deploy bug fixes and new features to production automatically as they check code changes into the repository. But a team creating phone apps to deploy to an app store may find that continuous deployment is not an option.
These two examples are cases where it is obvious the new practice won’t work, but many practices will not work in some environments for more subtle reasons. For example, a team may be writing new code for Extract, Transform, and Load (ETL) processes. The team may consider using TDD but discover the TDD practice leads to wasting too much time writing and rewriting tests that primarily mock calls to databases and offer little assurance that the code will work even if it passes those tests.
Context matters! Don’t assume that a practice providing great benefits in one context will be just as successful in other contexts. You have probably read articles or heard presenters touting the benefits of practices such as Scrum, TDD, Pair Programming, or Continuous Delivery; and declaring that all software developers should use these practices. Don’t fall for it! Be a little skeptical! Learn more about the practice and consider your context to decide if it is right for you to try. If you try the practice and it doesn’t work, that doesn’t necessarily mean you are doing it poorly, it may mean that the practice is not right for your context. If you really want to use the practice, you may be able to make it successful by changing other elements in your context first.
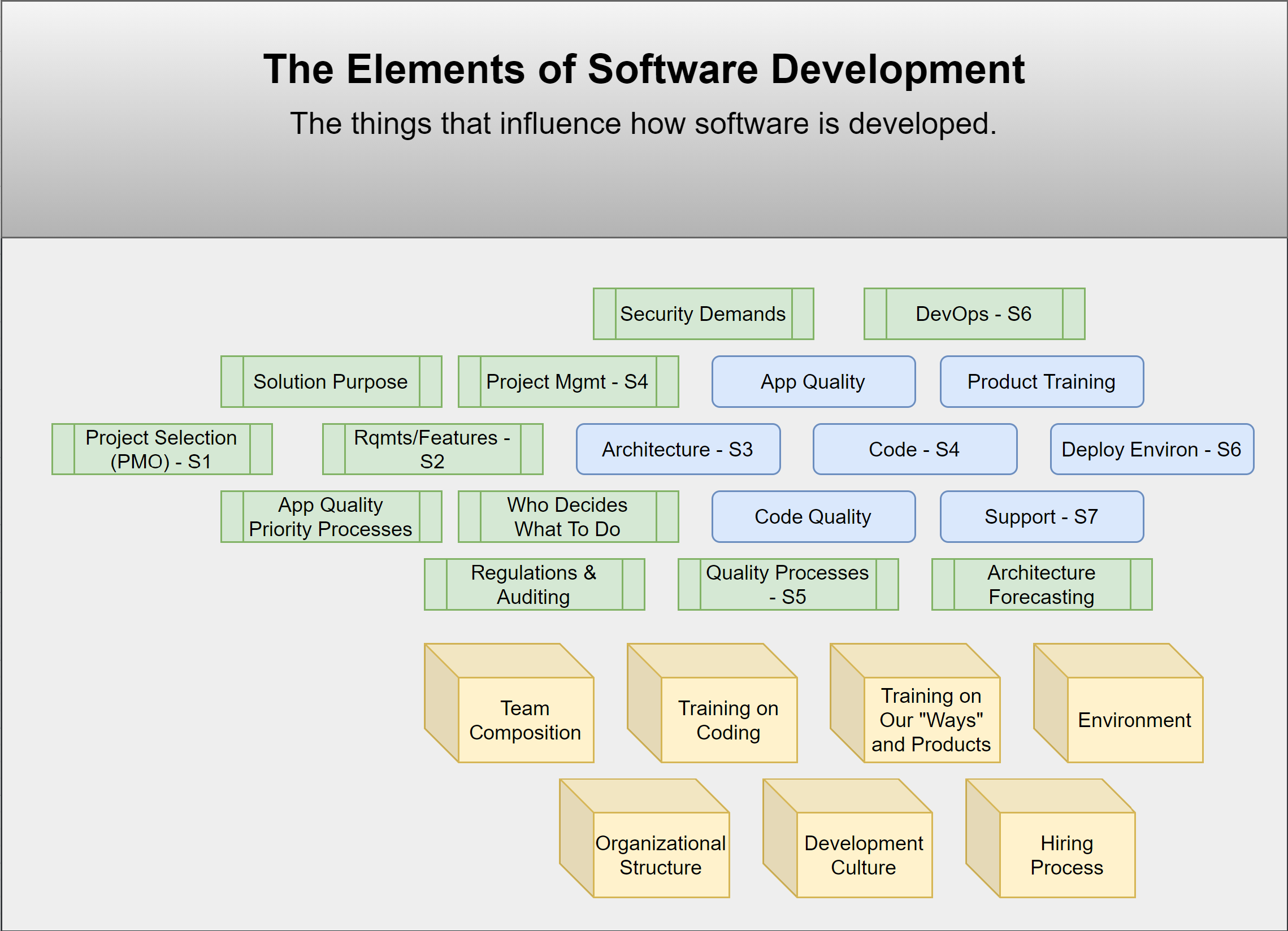
Successful software products and solutions rely on much more than the programming source code put into them. The elements attempt to identify all the factors that affect the outcome of a software development project. The value of recognizing each of these elements is to help those involved in a software development process recognize that many elements influence the production of quality software, and each of these elements should be evaluated if you desire to improve your software product and software development processes.
Most people accept, as self-evident, that any process has room for improvement. The CPI (Continuous Process Improvement) mindset encompasses many programs and frameworks that accept that people can always do better and can systematically attempt to do so. If you agree that improvement is possible, it follows that you also recognize there are many areas in which improvements can be made. We can’t make all possible improvements simultaneously, therefore we must select a few things to improve and start those before identifying and working on other areas of improvement.
The elements give us places we can look to consider making improvements. We will find that it is easier to make improvements in some of the elements than in others, but we should also consider which improvements provide the best return on investment (ROI) when undertaken. We hope practitioners will examine each of the elements and consider if changes could be made that would improve their software development process and product, and direct their energy to those changes that will most likely be successful and provide the best ROI.
The elements of software development are the things that influence how software is developed.
Each element has been assigned a category, either Product, or Process, or People. Elements assigned the people category are elements that affect the development of people. When you make a change to one of the people elements, you are usually making a change that you hope will improve a person or people. When people have better training, experience, tools, and workplace satisfaction they are more likely to produce better software. Elements assigned the process category are elements that are used to produce the product, but that are not present within the product delivered to the client or people that use the product. Agile methods and DevOps are two very notable elements assigned to the process category that have a significant impact on the successful delivery of a quality product. Of course the elements of the product category include those things the customers interact with, including training and support along with the quality of the software.
Product is what the customer is buying; process is how that product is created; people are those using the process to create the product.
On nomenclature: The word element and category are lower case for a reason. There is nothing special or significant in the choice of these words. The word element was selected primarily because it is less used in software literature than many synonyms that could have been used such as component, factor, feature, or module. Likewise, category is used extensively in the domains of many fields, but in this article it is a simple term used for grouping some similar elements.
The Software Development Life Cycle (SDLC) has long been considered the list of steps followed for the production of software. The elements makes no change to that. The elements identify additional factors that influence how software is produced and that affect the success or failure and quality of the software. Nine of the elements are noted for having a close correlation in meaning to a step in the SDLC.
SDLC is the name for the process we use to get from Idea to Solution.
The first purpose of the elements of software development is to help us identify where we might spend our time to make improvements. The second purpose of the elements of software development is to help us identify the current context in which we develop software so that we may make better selection of practices and processes that will lead to success. There are hundreds of practices and processes to choose from to use during software development, and much debate about which practices and processes are best. The truth is that the value of any specific practice or process depends a lot much upon the context in which it occurs. Perhaps this is best understood from this example: Some software developers believe strongly in CI/CD and believe that all development teams should make it a goal to deliver software continuously. However, other software developers work in a context where that is not possible. For example, continuous delivery of software embedded into gyroscope controllers on a Mars rover craft is impossible. Even for many contexts where it would be theoretically possible to apply CI/CD, the benefits and risks are not worth the cost of doing so.
The value of a practice or process must be considered within the context in which it is applied. Of the twenty-five elements, all but three contribute to the context in which software is developed. Therefore, when we consider the use of a different process or practice, we should consider our context as a factor that may make that process or practice successful. Many software development teams have adopted the Scrum methodology in an attempt to improve their software development. Unfortunately, the adoption of Scrum has not been successful in every case. But why is that? Is it because they are doing Scrum incorrectly, or is it because Scrum is not a good practice for their context? That is a difficult question to answer. Unfortunately, a few people dogmatically believe Scrum should always be used by all teams, and that could be based on their own lifetime of experience, which could be all within similar contexts. These people then may continue to push Scrum even when it is not the best choice in a different context. This is the outcome we hope to avoid when practitioners consider the context into which they are attempting to apply a practice.
The context for software development for a team reflects the collection of twenty-two of the elements. The context is the interaction of these twenty-two elements. The implication is that you should ask if the practice you are considering to adopt is a good practice for your context. Is it a good practice that aligns with your choices for each of the twenty-two elements that apply to context? A few examples of processes and practices, Scrum and CI/CD, were already mentioned. Other examples of processes and practices include Test Driven Development (TDD), Pair Programming, Unit Tests, Automated Builds, Kanban, Retrospectives, Estimates, Metrics, WIP Limits, Story Points, StandUp Meetings. There are many more.
The hope is that we can use the identified context to make a good selection of practices. Here is an example that considers just a few of the context elements along with the question, “Should we develop software using TDD?” If the “Team Composition” is “junior developers”, and the “application architecture/design” is “unknown”, then asking them to use TDD when they have not done so before may be very valuable to achieving good results. But if the “Team Composition” is “senior developers”, and the “application architecture/design” is “well known”, then asking them to use TDD when they have not done so before may be detrimental to the results. TDD, or any other practice or process, is not inherently always good or bad, but these patterns and practices work better in some contexts than others.
Context is the collection of factors that influence the choice of best practices for your software development processes.
The twenty-five elements of software development are used by most software development teams, but not all. For example, software developed by a single person is unlikely to have a “Hiring Process” element. However, for each of the twenty-five elements, a software development team made a choice about what to use within each element. Here are a few examples. For “Architecture”, the choice could be a web application, desktop application, embedded application, or another architecture. For “Project Management”, the choice could be Scrum, Kanban, Waterfall, or another process. Every software product under development is being developed in a specific context, and that context affects best practices. Many people probably also understand that the context is rarely static. A team that is developing an application using one process many also be transitioning to developing the application using a different process.
As mentioned previously, it is probably counter-productive, destructive, or simply impossible to systematically make changes to all the elements of your software development at the same time. You must select some to begin improving, which means you must choose those that are most valuable to change first. Even when someone can show you that there is value in changing the way you handle one of the elements, you might not begin making that change because there are more valuable things to focus your efforts on. The one limiting factor that all software developers share is limited time.
We have a limited amount of time to spend on creating software and improving processes before the results of our efforts becomes obsolete. Therefore we must choose wisely how we spend our time. What changes will produce the most benefit, do the least harm, or introduce the least risk?
The elements of software development are shown in a list that includes some questions related to each element to help developers understand what they represent. Future articles will cover each item in more depth. Another track of future articles will look at software development practices one by one and consider which implementations of each element could be benefit from the practice and which it could be a detriment to.
Prologue: Software Practices Are Only Best Within Specific Contexts
Have you ever attended a conference session with a presenter that is very passionate about a new process? They believe that everyone should be using the process. Often, I have doubts that the process will work for my team, but the presenter seems to imply that I don’t fully understand what they are attempting to convey; and perhaps I just need to start trying to make the change to realize the value of it. While this could be true, I have learned over the years that many people pitching process changes that provided enormous return on value for their software development teams, are pitching solutions that might not work well for other software development teams. The presenters are not trying to sell me something I don’t need, and they are not being dishonest, they are usually just considering their solution from a single context.
And what do I mean by context? A context is the processes, people, tools, networks, languages, deployment models, and culture in which software is produced and deployed. A practice that is optimal in one context may not be optimal in another, just like the best practices for building a house may differ from the best practices for building a bridge or a skyscraper. Some aspects of context affect some best practices more than others. For example:
Your deployment model is an aspect affecting the processes you choose. It is possible to use the CI/CD process when you deploy to a web app, but impossible to use CI/CD when deploying software to chips that are embedded in the engines of airplanes.
StandUp meetings might be ideal for a scrum team with all members co-located and starting work at the same time; but a waste of time for a team of four all sitting at the same desk doing mob programming.
This series of articles looks at software practices one by one to highlight what contexts each practice may work well in, and contexts where the practice may not work well, or may even be counter-productive.
Here is an example of a context constrained best practice. After graduating from college, a developer created static web sites for years, modifying html pages and JavaScript and committing code changes to GitHub while also maintaining a web server and uploading file changes to the web site using FileZilla. But then he discovered Netlify which uses the JamStack process which makes it incredibly easy to commit his changes to GitHub and have them validated, compiled, optimized, and automatically deployed to the production web site. Now he is telling everyone they should use JamStack and Netlify for all web development. And perhaps they should, if they are deploying static public web sites. But some developers are deploying to internal web sites. Some developers have database changes and dependencies on code from other teams. Some developers have mission critical applications that can’t risk ten seconds of downtime due to an error in production. These are different contexts and the Netlify/JamStack approach may be undesirable for these contexts.
In short, any “best practice” applies within a specific context, and is unlikely to apply to all contexts. We need to identify the best practices that we can apply to our contexts. Some people are dogmatic about their ideas of best practices. They believe a process should always be applied in all software contexts, but personally, I think there may be no software practice that is always best. I think there are many contexts in which some process recommendations are poor choices.
Subsequent articles will examine processes one at a time, explaining why the processes are poor choices for some contexts. The list of process recommendations that will be shown to be poor choices in some contexts include the following: Scrum, TDD, Pair-Programming, Continuous Deployment (CD), Story Points, Velocity, Code Reviews, Retrospectives, Management By Objectives (MBO), and metrics.
Main Content: Is CI/CD Right For You?
The acronym CI/CD stands for “Continuous Integration” and “Continuous Delivery” and also “Continuous Deployment”. Usually, perhaps always, CI needs to be implemented before either of the CDs can be implemented. CI refers to coders pushing code changes to a shared team repository frequently, often multiple times per day. In many contexts, a build of the software is started once the push into the shared code base is complete. In some contexts, builds of the shared repository may occur on a regular basis such as every hour. The benefit of automated builds is to quickly identify cases in which the code changes made by two developers conflict with each other.
Along with running a build, many CI pipelines perform other tasks on the code. These tasks include “static code analysis” aka “linting” to determine if the code follows code formatting standards and naming conventions as well as checking the code for logic bugs and bugs that create security vulnerabilities. Static code analysis may detect if new and unapproved third-party libraries were introduced, or that code complexity levels exceed a tolerance level, or simply if a method has more lines of code within it than is approved by company standards. If the code compiles and passes the static code analysis checks, it may then have a suite of unit tests and integration tests executed to verify no existing logic in the application was broken by the latest code changes.
CI encompasses two practices; frequent code pushes and automated builds. Some of the benefits of frequent code pushes include:
Developers get feedback more quickly if they have made changes that conflict with something other developers committed,
Builds based on the shared repository are less likely to conflict with changes from other developers when the code base the developer is working from is more current and the number of changes made to the code is fewer,
Reviewing code of other developers is easier when developers check in frequently because it is likely there are fewer code changes to review,
Since code reviews take less time, they interrupt the flow of the developer reviewing the code less,
Since code reviews take less time other developers are more willing to perform the code review and are more willing to do it soon.
Some of the benefits of automated builds include:
A relatively quick response if code pushed to a shared repository causes a build failure,
Relatively quick feedback from static code analysis tools to identify problems,
Relatively quick feedback from unit tests and integration tests if code changes created bugs in the application.
CI is very beneficial and invaluable to many software development teams, but it is not necessarily a benefit in all software development contexts. Some contexts that may gain little value from CI include:
When there is only a single developer on the project and a CI environment does not already exist,
When developers are exploring a new programming language for development. In this case, the time required to set up the CI may be more than it is worth for something that might get discarded,
When the coding language is a scripting language and there is no compile step,
When a team has no automated build currently and creates the compiled version of their product on their local machines to deploy to production.
Should You Make a Process Change?
When evaluating if any process like CI is good for you, the most important factors in making the assessment are:
Is it worth my (our) time to implement the process or practice?
Will the process improve our product quality?
If the process does not improve quality, which means it doesn’t decrease bugs or decrease security vulnerabilities or improve application performance; and it takes significantly more time to implement the process than it will save by not implementing the process, then you should probably not implement it.
Should You Consider CI?
With this definition of CI and criteria for assessment, I believe that most development teams should consider implementing CI into their development process.
CD Benefits and Drawbacks
The other aspect of CI/CD is CD. CD stands for either “Continuous Delivery” or “Continuous Deployment” or both. Both terms imply that successful software builds get automatically pushed into an environment where it can be tested or used, but some teams prefer to use “Delivery” for non-production environments and reserve “Deployment” for the “production” environment. Also, some teams don’t really automatically deploy the software to an environment after it successfully builds. Instead, the deployment to an environment requires a button click by an authorized person to proceed.
CD has less adoption than CI, partially because CI is generally a pre-requisite to CD, but mostly because CD is not a good deployment strategy for many software products. In fact, CD is not even possible for software embedded onto chips and placed into airplanes, cars, refrigerators, rockets, and many other devices. Nor is CD practical for most desktop applications and applications delivered to phones and other devices through an app store. CI/CD is most likely useful in the deployment of web applications and web APIs.
Some of the benefits of Continuous Delivery to a non-production environment include:
It forces you to codify everything. That means you need to figure out how to automate and automatically apply the environment specific configuration values. You may need to learn how to use containers to simplify deployment and to version control and automate all aspects of devops,
It creates possibilities. For example, once you have taken the time to create a pipeline where your automated build can flow into a deployed environment, you discover you can now easily automate your pen tests and stress tests against a test environment,
A developer can test some changes in a deployment environment that they can’t test in the developer’s environment (aka: works on my machine), such as:
Changes related to threading behavior in applications,
Changes related to users from multiple devices simultaneously using the application,
Stress testing the scalability of an application,
Testing features affected by security mechanisms such as OAuth and TLS.
Developers can get new features into functioning environments faster for the benefit of others,
Developers can deploy to testing environments easily without waiting on the devops team or IT team to perform a task for them,
It becomes easier to create a totally new environment. Perhaps you currently have just production and test. Now you can add a QA environment or a temporary environment relatively easily if all the deployment pieces are automated.
Some of the benefits of Continuous Deployment to a production environment include:
Developers can get new features and fixes to production faster. This is very valuable for static sites. This is a core feature of most JamStack sites.
Developers can deploy without waiting on the devops team or IT team to perform a task for them.
Some of the challenges of Continuous Delivery to a non-production environment include:
Applying changes to databases in coordination with changes to code,
Interruption of testing by others currently in process,
Insuring the correct sequence of deployments when multiple teams are deploying to a shared testing environment and some changes depend on sequence
Some of the impediments of Continuous Deployment to a production environment include:
The need for the software to be burned into a physical chip,
The need for the software to be published through an app store,
The need for lengthy integration testing and/or manual testing before production, often due to the need to insure the software is correct if it is used to keep people alive,
The desire by the company to find any problems with the software before customers interact with it.
Should You Consider CI/CD?
Should you adopt CI and/or CD? That is a question you need to answer for yourself. Not only should you consider the benefits and value CI/CD may bring to your development process, you should always also consider if adopting a process is more valuable than other changes you could make. Just because we recognize the value in implementing a specific change doesn’t mean we should implement it right away. Perhaps it is more valuable to your company to complete a project you are working on before implementing CI/CD. Perhaps it is more valuable to wait six weeks for the free training sessions on TeamCity and Octopus Deploy to be available if those are the tools you are considering to use for CI/CD. Perhaps you are considering moving from subversion to git. If so, you should probably make that change before you build a CI/CD solution, otherwise you may need to rebuild your CI/CD pipeline completely. Also, going from manual builds to CI/CD is unlikely to be something completed in a short time frame. It is something you will progressively implement and adopt more aspects of over time.
I believe that most development teams should consider implementing “Continuous Delivery” into their development process. “Continuous Deployment” to production is probably primarily of value to teams deploying static web sites, and maybe a few sites with small amounts of data or unimportant data.
Average programmers get the job done. Excellent programmers get the job done too, but the code of excellent programmers lasts longer and is easier to change to meet future requirements. Below is an example of upgrading average code to excellent code.
Our team decided an application could benefit from caching some data in our .Net application. We selected a caching framework with a good reputation and implemented it in one of our business objects. Here is the code:
private static IAppCache _cache = new CachingService();
public static IList<Zone> AllZones
{
get
{
return _cache .GetOrAdd("zones", () => ZoneManager.LoadAll(), new
DateTimeOffset(DateTime.Now.AddHours(1)));
}
}
The code worked and we noticed a performance improvement in our Zones class. The code was easy to implement. We decided we would implement something similar in several other classes. However, the above code is just “average”. What I mean by that is while “it works”, it could be made better. Allow me to talk through many of the considerations carefully.
If the code solved a problem and we desperately needed to get it into production right away to keep from losing thousands of dollars per hour, then we should probably deploy it right away. The business need is more important than the developer’s preference for robust code.
If this was the only place in the application that would need this type of caching logic and it is working well, then the code is probably “good enough” and needs no further consideration or enhancement.
In fact, if this code works as is, and would never need to be modified again, spending additional time to enhance the code (from good to excellent) would actually be a failure. It would be a waste of time, assuming that the developer(s) involved had alternative activities they could engage in that would add more value to the software or the developers skills than refactoring the above code.
If the above code exists specifically for a short-term project, and it will be deleted and no longer used within a week, and refactoring would not improve performance, but would just make the code easier to maintain in the future, but the code really has no future; then refactoring the code is pretty much a waste of time.
In our application, the above caching code was the start of a pattern for caching we wanted to implement in other business objects. Whenever you are starting some code that will be the pattern by many developers across the code base, you probably want to think about improving the code in the following ways:
Make the code as easy to implement in each place as possible. That means:
minimizing the references you need to add for each implementation;
minimizing the properties and methods and supporting features you have add each time you use it;
minimizing the code changes you need to make as you copy/paste it from one place to another.
You want developers to fall into the Pit of Success. This means you want to make it easy for everyone using the pattern to get it right. The fewer changes they have to make, and the more obvious those changes are, the more likely the other developers will successfully implement similar code in other places.
We were aware that the framework we used for caching could change. We started with a framework called LazyCache that uses the IAppCache interface and CachingService, which you can see in the code above. But what would happen if we decided we needed a different caching framework in the future? We might have to go back to each business object and change the interface we used, and probably replace CachingService. Can we refactor this code to make it unlikely the code in the business object needs to change if we decide to use a different caching technology such as Redis? I believe the answer is ‘yes’. Our goal then becomes the following:
Move all the code specific to our caching technology (LazyCache in this story) into a separate class, so that our business objects are totally unaware of the technology used for caching.
Pass all the values and method needed for the caching feature from the business object to the new caching class we create.
Minimize the things we need to pass to the caching framework to make the code easy to implement in each business object.
Write the caching class in a way so that it also does not need to know much about the business objects that it is caching. Make sure that it does not need to reference those business objects.
Write code so that the caching class does not need to be changed when it gets used by additional business objects. It can become a “black box” to future developers.
The revised code in the business object looks like the following:
public static IList<Zone> GeoZonesFromCache
{
get
{
return CacheManager.GetOrAdd(CacheManager.ZONES, () => ZoneManager.LoadAll());
}
}
Notice that it no longer has any reference to the caching service. This should allow us to change the way the data is cached from using LazyCache to some other Caching framework including caching services like Redis Cache without needing to modify each business object. We pass the minimum information which includes the name of the cache (which is a ReadOnly string named CacheManager.ZONES), and also the function to run (ZoneManager.LoadAll) if the cache is not already populated.
We did have to write more code in our CacheManager. Here is the code:
using LazyCache;
namespace MyApp
{
public static class CacheManager
{
private static DateTimeOffset GetCacheDuration(string cacheType)
{
return new DateTimeOffset(DateTime.Now.AddHours(1));
}
private static IAppCache _cache = new CachingService();
public static IList<T> GetOrAdd<T>(string cacheType, Func<IList<T>> itemFactory)
{
return _cache.GetOrAdd(cacheType, itemFactory, GetCacheDuration(cacheType)) as IList<T>;
}
public static readonly string ZONES = "zn";
}
}
In the code above I include a using statements, for LazyCache. This is the only class in the entire application that references LazyCache. If we decide we want to replace LazyCache with Redis cache or some other cache then this one class should be the only place in our app where we need to make a change.
Is the code that we wrote perfect? The answer to that is definitely ‘Maybe’. We can’t know if existing code is perfect until time has passed and we determine if it met our needs. I believe that the code has to meet these criteria to be considered perfect:
If the code never needs to be changed, then it was perfect,
If the code does need to be changed, but it is easy for the developer to change in order to adapt to a requirement change, then it could still be considered perfect when originally written, especially if the changes are isolated to the CacheManager class and don’t need to be made in each business object that uses it.
If changes are needed in each business object, but the changes are easy to implement and were not foreseen when the code was first written, then you could still consider the original code to be perfect. For example, perhaps some business objects need to pass the cache duration into the CacheManager service. Assuming that code is easy to implement, and it was not originally expected and coded for, then the original code could still be considered perfect.
Some of you may identify that improvements to the CacheManager are still possible, and that is certainly true. One improvement would be a change to make it easier to write unit tests for the business objects using CacheManager. The code I have above is hard-coded to use the “CachingService”. It could be helpful if the “CachingService” could be mocked away in unit tests, especially if you replace the CachingService with Redis Cache. Fortunately, given that the caching code is contained within a single class, it would be fairly simple to change the CacheManager to use an IOC framework. I won’t delve into that here other than to point out that part of writing excellent code might include the ability to unit test that code you have written. I will also point out that the refactored code (from “Average” to “Excellent”) makes the writing of unit tests to test the CacheManager itself easier.
You may also notice that the code contains no error handling. I did not include error handling because it would add clutter that is irrelevant to the topic of this article, and also because some programmers may prefer errors to bubble up the call stack to be caught elsewhere in the application.
To recap this article, if you want to go from being an average developer to an excellent developer in a scenario like this you should do the following:
Before writing code, first identify if there is already a solution to the problem in your code base and determine if you can reuse the same solution.
When you are writing code, ask yourself if part of the code could be re-used in other places in the application, or perhaps in the future.
Take some extra time to write the code in a way to make the pattern easy to implement correctly in every place it will be implemented (or at least in many of the places).
Write the code in a way to minimize the need for modifications to each business object if changes to the service being implemented are needed.
Make the places where the pattern is implemented unaware of the details of how it is implemented. In other words, the business objects have no idea what caching technology is used and won’t need to be altered if that caching technology is changed.
Make the pattern unaware of the specifics of the objects that are using it. In other words, the CacheManager does not need to be able to reference and understand the business objects that are calling it. There is no dependency there.
Don’t pass hard-coded strings. Use an Enum or string constants. This allows you to change the string value in a single place if you ever need to do so, and, more importantly, insures there are no string typos made. In the class above, this was done for the CacheType (CacheManager.Zone). We could have passed a literal string “zn” into the CacheManager, but we anticipate adding logic, perhaps a switch statement based on the cacheType to obtain the duration for the cache, which means we would have a second place (the switch statement) also with a hardcoded string of “zn”. By using a readonly variable we eliminate the risk of typos for that string.
This is not an article about caching. This is an article about taking code that is average and making it better, using the implementation of some caching logic as an example. Some of you may notice that our change to make the code better is also an example of “Separation of Concerns”. This is true, but the article is not about “Separation of Concerns”, it is simply about writing better code. Finally, I will point out that this example is also an example of the “Façade” pattern, but again, this is not an article about the “Façade” pattern, just an article about better code.
I hope this article helps some average developers along their journey to becoming excellent developers.
In my last article (https://csharpdeveloper.wordpress.com/2021/05/24/how-companies-can-facilitate-the-onboarding-of-entry-level-developers/) I wrote about things a company could do to improve the onboarding experience for entry-level developers. In this post I offer some questions that newly hired developers can ask to improve their own onboarding experience. Not only do I suggest that you ask these question, I think you should actively seek the answers to these questions if you have idle time. Knowing the answers to these questions will improve your understanding of how things are done at the company and impact how you write code and spend your time in development.
What do I need to do to be considered a contributor to the company?
One of your employer’s biggest concerns is the unknown number of weeks or months it will take before you provide more value to the company than the cost of your salary. No matter how talented you think you are, you almost certainly are costing the company more than you are worth for the first few months you work there, if not longer. And the reason for this is because a senior developer could complete all the work you did in your first two months in one-tenth of the time and with higher quality. So, if that senior developer has to spend half of their time during your first two months assisting you, then the company is going to be nervous that you will continue to cost them more than you are worth. However, take heart in understanding that your employer hired you knowing there would be an upfront cost, but in the hopes that you would soon be able to contribute more than you cost, and be able to contribute without requiring a lot of time from the other developers.
What percentage of my time will I spend using my JS/TS skills, my server-side skills, my database skills, (the skills that you hope to spend time on improving/learning)?
This question really should be asked before you get hired unless you really need a job soon. If you are craving to write TypeScript code but learn you will be tasked with writing database SQL for the next year, then you should definitely let your employer know your preferences because they may be able to make adjustments to improve your employment satisfaction.
Who will be using the software I work on? Is it external customers or internal employees? Are we developing applications for other businesses?
Most entry-level developers I hired rarely asked such questions, but I don’t think less of them for not asking. The reason I think newly hired developers should ask these questions is because it helps give the developer a better understanding of how the software works and is deployed. It helps the developer correctly assess the trade-offs between application concerns such as security and performance and the impact and risks of making mistakes.
How is the software that I will be working on deployed? Is it “in the cloud”? It is on premise? Is it web apps or desktop apps or phone apps?
Like my note on the previous question, this helps developers assess impact and risks of making mistakes, and also understand what technologies they may need to learn.
What is the process for our source code to get to deployed? Do we commit to a source control? Do we manually run build and deploy tasks?
In some companies, developers write code, check in into a repository, and then forget about it. In other companies the developer guides the code all the way into the production environment. The answers to these questions will help you understand what is expected of you and your role in the process and identify some things you need to learn.
Are there unit tests or static code analysis or other steps in the build pipeline?
Companies with more highly evolved software development practices often have static code analysis and unit tests. If your company does not have them, this identifies an area where they could possibly improve by adding them. If they already have these processes, then you should probably learn how to use them and gain their advantages.
If there are tests, how do we write and manage them?
Unit tests provide a lot of value for teams that continue to work on and evolve a software product. If your team is already using them, you should learn how you can add your own unit tests as part of the first lines of code that you will write yourself.
Are there database changes that might accompany our code changes, and if so, how is the deployment of the two together managed?
Many software products store data in databases, and often those are relational. If you make code changes that affected how the data is stored, then the change to the data store needs to be migrated into production along with your code changes. This can be challenging in many environments so you want to understand the impact and how it can be managed. You may decide in some cases that you will write your code in a different way to implement a feature just so that you can avoid a database change.
Is there a QA/Test environment that we can deploy to, and is there staff to test our changes?
This helps you understand how much responsibility you have for testing your code changes. Not that you shouldn’t always test your own code changes, but often a change you make could affect many scenarios, and a QA team can help reduce the time you need to spend testing. When a QA or Test environment exists, it tells you that the company is fairly concerned that bugs don’t get introduced to the production environment.
Who do I work with to review my code changes and to guide me toward writing good code?
A specific single person signals to that person that they are expected to work with you and therefore will dedicate time to do so. When there is “shared” responsibility, team members often hope that someone else on the team will help you because each team member is usually already very busy; and they each assume someone else is less busy than they are.
How do I receive the tasks that I am going to work on, and how does the team track my status on those tasks?
Most software development shops use a white board or some task management software. There are many free task management tools on the Internet like Trello, but most teams will have something more sophisticated. Learning how to correctly use these products is important for you in learning how to manage your work and to help your team members see that you are contributing.
How do the users of the software know all the features we put into it and what bugs exist and what bugs have been fixed?
Some products, especially software for internal employees, may not track this at all; but software for sale that is used by external customers probably does. As you fix bugs and add features those usually need to be shared with customers and understanding how that process works will help you contribute good explanations and information to the customers.
Who do I contact for non-technical questions about how features in the software should work?
Hopefully you have a mentor to help you write code, but you often need to talk to the users of the software, or a representative of those users, to better understand exactly what they would like to have done, or to collaborate with them about the costs of what they asked for and alternative ways to solve their problems.
Is there documentation for users of the software that I can learn from?
This is a great way for new developers to get up to speed more quickly on what is expected of them. Seeing the software from the end user perspective will help you understand what needs to be accomplished in the code you write.
Is there documentation about the software architecture and coding guidelines?
Internal documentation can help you make appropriate decisions, not just about formatting but also in helping you to identify that some problems have already been solved and you can, and should, re-use the existing proven solution.
Can I install software on my computer, or do I need to ask permission first?
Before installing software, get permission. Some companies provide a location with tools already approved for use. Many companies do not want you to download software from the Internet due to the risks that the software may contain malicious code. They will desire to first approve it. You don’t want to be the person that downloads the malware-laden software component that infects the company’s network with ransomware.
Are there policies I should follow before adding third party dependencies or components to the software we are writing?
Although a StackOverflow post may show how easy it is to include a third party JavaScript library in your web page to solve a problem; it might not point out that the license requires that the JavaScript library only be used in open source projects and any software that uses it should be considered open source. This can lead to lots of legal hassles. Make sure that you approve third party frameworks and tools that you use and honor their license agreements so that you don’t get your employer into expensive legal trouble.
What are the security threats I should be aware of when writing our software?
If you are asked to import an XML document into an application and process it, you should probably learn how concerned you should be with making sure that XML document does not contain malicious script that could do harm to the computers on which your code is installed. XML documents are just one example; many inputs and processes can introduce security risks. Learn early what the security threats are and also how your team correctly addresses those threats so that your code doesn’t open the door to malware.
Does our software need to adhere to compliance guidelines such as SOX, PCI, or HIPAA?
Like addressing security threats, some of the code we write, particularly some of the design and management of sensitive information like passwords and credit card numbers, has to be handled with extra care. It is likely that good practices have already been identified and you can borrow code from elsewhere in your applications to handle compliance guidelines; and it is best to learn the right way to do those things before writing code that just works.
Will I be exposed or working with any sensitive data and how should I handle it if I will?
Patient and customer data sometimes ends up in test databases so that developers have real data to test with. However, you should take care with the data and make sure it is not shared in printed pages, or on test web sites, or exposed to other people that have not signed the waiver that they will treat the data as confidential. Understand that some data you are dealing with should not be discussed outside of your business context.