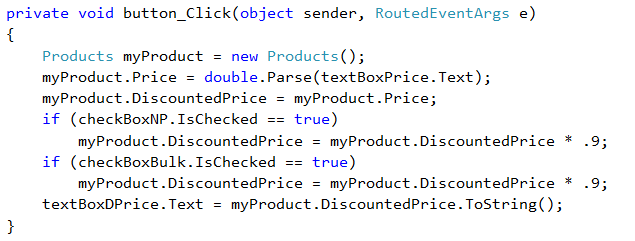
Average programmers get the job done. Excellent programmers get the job done too, but the code of excellent programmers lasts longer and is easier to change to meet future requirements. Below is an example of upgrading average code to excellent code.
Our team decided an application could benefit from caching some data in our .Net application. We selected a caching framework with a good reputation and implemented it in one of our business objects. Here is the code:
private static IAppCache _cache = new CachingService();
public static IList<Zone> AllZones
{
get
{
return _cache .GetOrAdd("zones", () => ZoneManager.LoadAll(), new
DateTimeOffset(DateTime.Now.AddHours(1)));
}
}The code worked and we noticed a performance improvement in our Zones class. The code was easy to implement. We decided we would implement something similar in several other classes. However, the above code is just “average”. What I mean by that is while “it works”, it could be made better. Allow me to talk through many of the considerations carefully.
- If the code solved a problem and we desperately needed to get it into production right away to keep from losing thousands of dollars per hour, then we should probably deploy it right away. The business need is more important than the developer’s preference for robust code.
- If this was the only place in the application that would need this type of caching logic and it is working well, then the code is probably “good enough” and needs no further consideration or enhancement.
- In fact, if this code works as is, and would never need to be modified again, spending additional time to enhance the code (from good to excellent) would actually be a failure. It would be a waste of time, assuming that the developer(s) involved had alternative activities they could engage in that would add more value to the software or the developers skills than refactoring the above code.
- If the above code exists specifically for a short-term project, and it will be deleted and no longer used within a week, and refactoring would not improve performance, but would just make the code easier to maintain in the future, but the code really has no future; then refactoring the code is pretty much a waste of time.
In our application, the above caching code was the start of a pattern for caching we wanted to implement in other business objects. Whenever you are starting some code that will be the pattern by many developers across the code base, you probably want to think about improving the code in the following ways:
- Make the code as easy to implement in each place as possible. That means:
- minimizing the references you need to add for each implementation;
- minimizing the properties and methods and supporting features you have add each time you use it;
- minimizing the code changes you need to make as you copy/paste it from one place to another.
- You want developers to fall into the Pit of Success. This means you want to make it easy for everyone using the pattern to get it right. The fewer changes they have to make, and the more obvious those changes are, the more likely the other developers will successfully implement similar code in other places.
We were aware that the framework we used for caching could change. We started with a framework called LazyCache that uses the IAppCache interface and CachingService, which you can see in the code above. But what would happen if we decided we needed a different caching framework in the future? We might have to go back to each business object and change the interface we used, and probably replace CachingService. Can we refactor this code to make it unlikely the code in the business object needs to change if we decide to use a different caching technology such as Redis? I believe the answer is ‘yes’. Our goal then becomes the following:
- Move all the code specific to our caching technology (LazyCache in this story) into a separate class, so that our business objects are totally unaware of the technology used for caching.
- Pass all the values and method needed for the caching feature from the business object to the new caching class we create.
- Minimize the things we need to pass to the caching framework to make the code easy to implement in each business object.
- Write the caching class in a way so that it also does not need to know much about the business objects that it is caching. Make sure that it does not need to reference those business objects.
- Write code so that the caching class does not need to be changed when it gets used by additional business objects. It can become a “black box” to future developers.
The revised code in the business object looks like the following:
public static IList<Zone> GeoZonesFromCache
{
get
{
return CacheManager.GetOrAdd(CacheManager.ZONES, () => ZoneManager.LoadAll());
}
}Notice that it no longer has any reference to the caching service. This should allow us to change the way the data is cached from using LazyCache to some other Caching framework including caching services like Redis Cache without needing to modify each business object. We pass the minimum information which includes the name of the cache (which is a ReadOnly string named CacheManager.ZONES), and also the function to run (ZoneManager.LoadAll) if the cache is not already populated.
We did have to write more code in our CacheManager. Here is the code:
using LazyCache;
namespace MyApp
{
public static class CacheManager
{
private static DateTimeOffset GetCacheDuration(string cacheType)
{
return new DateTimeOffset(DateTime.Now.AddHours(1));
}
private static IAppCache _cache = new CachingService();
public static IList<T> GetOrAdd<T>(string cacheType, Func<IList<T>> itemFactory)
{
return _cache.GetOrAdd(cacheType, itemFactory, GetCacheDuration(cacheType)) as IList<T>;
}
public static readonly string ZONES = "zn";
}
}In the code above I include a using statements, for LazyCache. This is the only class in the entire application that references LazyCache. If we decide we want to replace LazyCache with Redis cache or some other cache then this one class should be the only place in our app where we need to make a change.
Is the code that we wrote perfect? The answer to that is definitely ‘Maybe’. We can’t know if existing code is perfect until time has passed and we determine if it met our needs. I believe that the code has to meet these criteria to be considered perfect:
- If the code never needs to be changed, then it was perfect,
- If the code does need to be changed, but it is easy for the developer to change in order to adapt to a requirement change, then it could still be considered perfect when originally written, especially if the changes are isolated to the CacheManager class and don’t need to be made in each business object that uses it.
- If changes are needed in each business object, but the changes are easy to implement and were not foreseen when the code was first written, then you could still consider the original code to be perfect. For example, perhaps some business objects need to pass the cache duration into the CacheManager service. Assuming that code is easy to implement, and it was not originally expected and coded for, then the original code could still be considered perfect.
Some of you may identify that improvements to the CacheManager are still possible, and that is certainly true. One improvement would be a change to make it easier to write unit tests for the business objects using CacheManager. The code I have above is hard-coded to use the “CachingService”. It could be helpful if the “CachingService” could be mocked away in unit tests, especially if you replace the CachingService with Redis Cache. Fortunately, given that the caching code is contained within a single class, it would be fairly simple to change the CacheManager to use an IOC framework. I won’t delve into that here other than to point out that part of writing excellent code might include the ability to unit test that code you have written. I will also point out that the refactored code (from “Average” to “Excellent”) makes the writing of unit tests to test the CacheManager itself easier.
You may also notice that the code contains no error handling. I did not include error handling because it would add clutter that is irrelevant to the topic of this article, and also because some programmers may prefer errors to bubble up the call stack to be caught elsewhere in the application.
To recap this article, if you want to go from being an average developer to an excellent developer in a scenario like this you should do the following:
- Before writing code, first identify if there is already a solution to the problem in your code base and determine if you can reuse the same solution.
- When you are writing code, ask yourself if part of the code could be re-used in other places in the application, or perhaps in the future.
- Take some extra time to write the code in a way to make the pattern easy to implement correctly in every place it will be implemented (or at least in many of the places).
- Write the code in a way to minimize the need for modifications to each business object if changes to the service being implemented are needed.
- Make the places where the pattern is implemented unaware of the details of how it is implemented. In other words, the business objects have no idea what caching technology is used and won’t need to be altered if that caching technology is changed.
- Make the pattern unaware of the specifics of the objects that are using it. In other words, the CacheManager does not need to be able to reference and understand the business objects that are calling it. There is no dependency there.
- Don’t pass hard-coded strings. Use an Enum or string constants. This allows you to change the string value in a single place if you ever need to do so, and, more importantly, insures there are no string typos made. In the class above, this was done for the CacheType (CacheManager.Zone). We could have passed a literal string “zn” into the CacheManager, but we anticipate adding logic, perhaps a switch statement based on the cacheType to obtain the duration for the cache, which means we would have a second place (the switch statement) also with a hardcoded string of “zn”. By using a readonly variable we eliminate the risk of typos for that string.
This is not an article about caching. This is an article about taking code that is average and making it better, using the implementation of some caching logic as an example. Some of you may notice that our change to make the code better is also an example of “Separation of Concerns”. This is true, but the article is not about “Separation of Concerns”, it is simply about writing better code. Finally, I will point out that this example is also an example of the “Façade” pattern, but again, this is not an article about the “Façade” pattern, just an article about better code.
I hope this article helps some average developers along their journey to becoming excellent developers.
 The business owner asked the software developers to build a new web application for a single client. She said that the web app needed to be really fast. She told the developers this could be the first version of a new product that the company would build upon for years to come.
The business owner asked the software developers to build a new web application for a single client. She said that the web app needed to be really fast. She told the developers this could be the first version of a new product that the company would build upon for years to come.